Table of Contents
ESM Data Analysis Course
General Information
| Course Dates | to be announced |
| Course Times | to be announced |
| Course Location | online |
| Registration Deadline | to be announced |
| Course Fee | 400 Euros |
Note: If you would like to be notified once arrangements for a new round of the course have been made, please send a mail to wvb (at) wvbauer (dot) com to indicate your interest and I would be happy to send you a mail once there is an update (this way, you do not have to keep checking this website).
Course Description
The experience sampling method (ESM) is an intensive data collection technique, where individuals are prompted to respond to a questionnaire (e.g., containing questions about affect and various contextual variables) multiple times throughout the day and typically for multiple days. By assessing thoughts, emotions, perceptions, and behaviors repeatedly and 'in the moment', we can gain deeper and more valid insights into individual differences and processes of change and examine their relationship to contextual variables (instead of having to rely on cross-sectional data and/or data that is possibly distorted by recall biases). Other terms to describe this and related data collection methods include ecological momentary assessment (EMA), ambulatory assessment, time/event sampling, the diary method, intensive longitudinal assessment/data, and real-time data capture.
Such data collection techniques yield a large number of repeated measurements on multiple variables per individual. The analysis of such data therefore poses particular challenges for researchers. Classical analysis techniques (such as repeated measures ANOVA or MANOVA) are not typically useful in this context, as they cannot easily handle the complexities involved (e.g., missing data, unequally spaced time points, time-varying covariates, autocorrelated residuals). Instead, multilevel (mixed-effects) models are typically the method of choice for the analysis for such data.
The purpose of this course is to describe how intensive longitudinal data can be analyzed with appropriate mixed-effects models. After a brief introduction to ESM (and related methods) and the data structures that arise from studies using such data collection techniques, we will examine models that can account for the multilevel/hierarchical structure of the data (i.e., repeated observations nested within individuals). This includes models with random intercepts, models with random intercepts and slopes, and models allowing for correlation in the residuals (serial/autocorrelation). Models with more than two levels (e.g., repeated observations nested within days, which in turn are nested within individuals) will also be covered.
An important issue in any modeling process are the model assumptions. We will therefore examine methods for checking the model assumptions (e.g., examining the distribution of residuals and random effects; checking for conditional independence, linearity, and outliers). Additional time will also be devoted to issues such as model selection, model comparison, and testing (e.g., estimation methods, Wald-type tests, likelihood ratio tests, information criteria).
The emphasis in the course will be on models with quantitative/continuous outcomes. However, other types of outcomes (e.g., dichotomous, multinomial, ordinal) also arise in practice. We will therefore take a look at appropriate models for such outcomes (e.g., mixed-effects logistic regression). Next, some psychometric topics (reliability, validity, and factor analysis with multilevel data) will be discussed. Finally, we will cover some miscellaneous topics such as centering of predictors, using lagged predictors, computing R²-type measures, power analysis, and some further model extensions.
The course consists of a mixture of lectures and computer exercises to cover not only the theoretical background, but also provides practical experience with analyzing real ESM datasets. Emphasis throughout the course is on the application of the various methods and the interpretation of the results. References can be provided to those interested in further mathematical/statistical details.
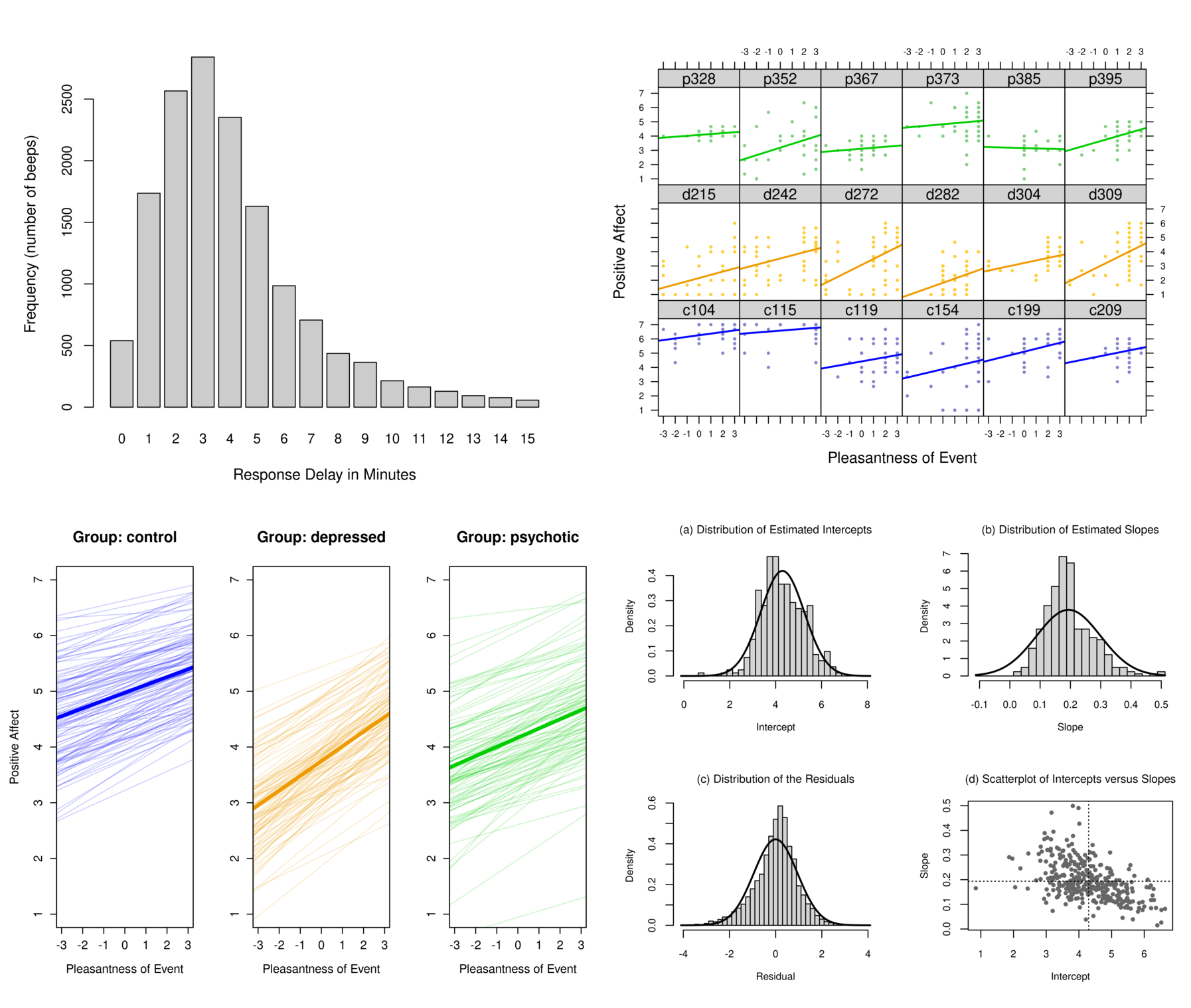
Course Schedule
Note: Given the dynamics of a live and interactive course, this schedule is tentative. Also, while the starting time for each day is definite, the ending times can vary a bit (by ±30 minutes). Also, shorter breaks are not indicated in the schedule, but we will take them as needed.
| Day 1 | |
|---|---|
| 09:00-09:30 | Introduction / Logistics |
| 09:30-11:30 | Lecture 1: An overview of experience sampling and related methods |
| 11:30-12:30 | Exercise 1 |
| 12:30-13:30 | Lunch |
| 13:30-16:30 | Lecture 2: From regression to the random intercepts model |
| 16:30-18:00 | Exercise 2 |
| Day 2 | |
| 09:00-10:00 | Lecture 3: Models with random intercepts and slopes |
| 10:00-11:00 | Exercise 3 |
| 11:00-12:00 | Lecture 4: Models with residual serial correlation |
| 12:00-13:00 | Lunch |
| 13:00-14:00 | Exercise 4 |
| 14:00-15:00 | Lecture 5: Models with more than two levels |
| 15:00-16:00 | Exercise 5 |
| 16:00-17:00 | Lecture 6: Model assumptions & model selection/comparison/testing |
| 17:00-18:00 | Exercise 6 |
| Day 3 | |
| 09:00-10:00 | Lecture 7: Models for other outcome types |
| 10:00-11:00 | Exercise 7 |
| 11:00-12:00 | Lecture 8: Psychometrics (reliability, validity, factor analysis) |
| 12:00-13:00 | Lunch |
| 13:00-14:00 | Exercise 8 |
| 14:00-16:00 | Lecture 9: Miscellaneous topics |
Course Prerequisites
In general, all efforts will be made to make the course as self-contained as possible. However, basic knowledge of statistical methods (e.g., regression, analysis of variance, hypothesis testing, factor analysis) will be beneficial to better appreciate the application of these methods in the present context.
Also, while a brief introduction to the experience sampling method is provided at the beginning of the course, this course is primarily focused on the statistical methods used for analyzing ESM / intensive longitudinal data. Those seeking more in-depth coverage of the background and the methodological/practical aspects of conducting ESM research might be interested in the general ESM Course which is offered by members of my department once or twice per year.
Finally, the primary software package to be used for the analyses during the course will be R (see below for more details on R and how other software packages will be accommodated). Although everything that you need to know to do the computer exercises will be explained in the course, this is not a comprehensive R programming course. Therefore, if you are new to R, it would be useful to familiarize yourself with R a little bit ahead of time (see also my notes on preparing to use R).
How to Prepare for the Course
The course will be given online via the video conferencing platform Zoom. While it is possible to join the course simply via your browser, I would not recommend this (certain features are not available via the 'web client' and the video/audio quality tends to be poorer). Therefore, I would highly recommend to install the Zoom client (which you can get here).
We will conduct a number of practical exercises throughout the course where we make use of the statistical software package R. Therefore, please download R from the Comprehensive R Archive Network (CRAN). Choose the appropriate "Download R" link depending on your operating system and follow the instructions for downloading and installing R. If you already have R installed, please check that it is the current version (you can check what the 'latest release' of R is by going to CRAN and then compare this with the version shown when you start R). If you do not have the latest version installed, please update.
Although not strictly necessary, it will be useful to also install an integrated development environment (IDE) for R. A popular choice these days is RStudio. So, unless you already have a different setup, please download and install RStudio.
One of the big advantages of R is that it is freely available and runs on a large variety of operating systems. Moreover, R has also become the 'lingua franca' of statistics and the software of choice for analyzing data in various disciplines. However, course participants familiar with and with access to other statistical software capable of conducting multilevel analyses are of course welcome to use it. I can accommodate (i.e., provide support and make datasets/scripts available) to users of SPSS and Stata. Users of other software (e.g., SAS, Mplus, HLM, MLwiN) are welcome to use it, but support will be limited.
Course Registration
At this time, it is not possible to register for the course. The course registration form will be posted as soon as another round of the course is organized.
Notes / FAQs
- The starting time of the course was chosen so that people from Europe, Africa, and Asia (and possibly Australia) can participate in the course without having to be up in the middle of the night (although people far East will need to be up quite late). My apologies to people from North/South America for whom these times are probably not feasible (a future round of the course might run at times more suitable for those from these regions).
- In the 'in person' courses that I teach, I often end up troubleshooting general computer problems for some of the course participants. I will not be able to do this in this course. Therefore, make sure to sort out any problems with installing the necessary software ahead of time.
- The course fee is meant to be paid per person. While I won't take active measures to check if a single person is behind each connection during the course, I appeal to your sense of fairness to register individually.
- The course will not be recorded. By registering, you also agree not to make any recordings of the course on your end.
Miscellaneous Information
| Instructional Language | English |
| Min/Max Number of Participants | 20/100 |
| Certificate for Participation | Upon request |
| Number of European Credit Points | 1 |